
Synthetic Biology
Commanding the Language of Life

Housekeeping - Newsletter Revamp:
First off, RD ended up selling our assets to a larger APAC based manager, so moving on to next opportunity soon
As such, this publication will be converted back into my personal blog under the resurrected pseudo @PonderingDurian :). I will still write about crypto / APAC tech, but now I have broader license to explore novel topics to which I’m drawn
Today, synthetic biology is at the top of that list.
“We program computers to manipulate bits, but we program cells to manipulate atoms. Cells are the building blocks of our food, our environment and even ourselves”
- Ginkgo Bioworks 2022 Annual Report
Programming Cells
I will readily admit, this is a full Beijing eight-lane highway outside of my lane. Luckily for you, I don’t care. The promise of programming cells, directing the language of life, as easily as we have come to manipulate the 0s and 1s which have infiltrated every facet of our lives is simply too transformative not to put under the microscope (sorry).
Staring back from the vantage of 2023, the invention of the transistor at Bell Labs in 1947 is in contention for the most important invention… ever. The manipulation of electrons through silicon wafers, interpreted as 0s and 1s by the processors lacing our pockets, our cars, our company clouds, and our militaries has been matched in its impact only by the complementary engineering grit and ingenuity which has allowed Moore’s law to continue unabated.
Number of transistors on microchips over time (LOG SCALE) predictably leads…

Our skyrocketing computational capacity….

The TikTok dance video you watched this morning. The microelectronics which govern your steering. The GPUs powering the GPT search which suggested the above graphs - all made possible by the world’s most complex manufacturing supply-chain built to digest ever more electron zaps on a single piece of silicon.
In many ways, the last 75 years could be told1 most appropriately through the lens of micro-electronics which has arguably shaped communication, entertainment, economics, and geopolitics more than any other trend.
However, the revolution has largely been restricted to the digital sphere. This sphere is slowly encroaching on all other industries through sensors, robotics, networking and more, but the information revolution has yet to bear the same fruit in the world of living organisms (sorry again).
My initial, under-educated, foray into the world of biology would suggest this is about to change.
The Language of Biology
To put it succinctly, we are slowly discovering the language of life. It turns out, the 0s and 1s which have underpinned the information revolution are not so different from the four nucleotide bases (A,T,G,C) which construct the now famous double helix of DNA in the genome: the software for cell construction.
The sequence of the DNA base pairs is transcribed by mRNA (think molecular fax machine) into the ribosomes (think molecular manufacturing facility) which read the sequence and begin constructing the amino acids which make up proteins which perform the essential functions for cell life.
While still early innings, we have come a long way in deciphering the genetic information which programs the cellular machinery behind life itself. Once you wrap your head around this fact, it becomes hard to think about anything else!
If Newtonian physics was the language of the industrial revolution, then atomic physics was the language of the digital revolution.
The digital revolution in turn has produced a new language - artificial intelligence - which holds great promise in unlocking the secrets of biology.
I will venture to argue the largest beneficiary of the recent advances in artificial intelligence (neural networks, large language models, and the advanced compute which enables them) is biology. As opposed to physics and computers which follow deterministic universal laws, biology has more complexity. Many genes (the software of life) are not monogenic (meaning one gene = one trait) but are polygenic, (each trait is impacted by a large number of genes in combination). Furthermore, there are a plethora of ways in which environment and randomness can impact both genes (mutations) as well as the transcription / translation process from genes to a unique protein.
This creates a staggering number of potential combinations from the relatively simple, elegant base pairs.

Source: Google’s DeepMind AlphaFold Initiative
Fortunately, the cost of acquiring, storing, and analyzing ever larger data sets is decreasing dramatically. The collision of big data, AI, and precision genome editing tools betray our position on the precipice of a decade of technical breakthroughs in programming life: a toolset which has broad applications across therapeutics, agriculture, synthetic materials, and more.
Why Now?
Three catalysts in particular have arrived which put the programming of cells within reach.
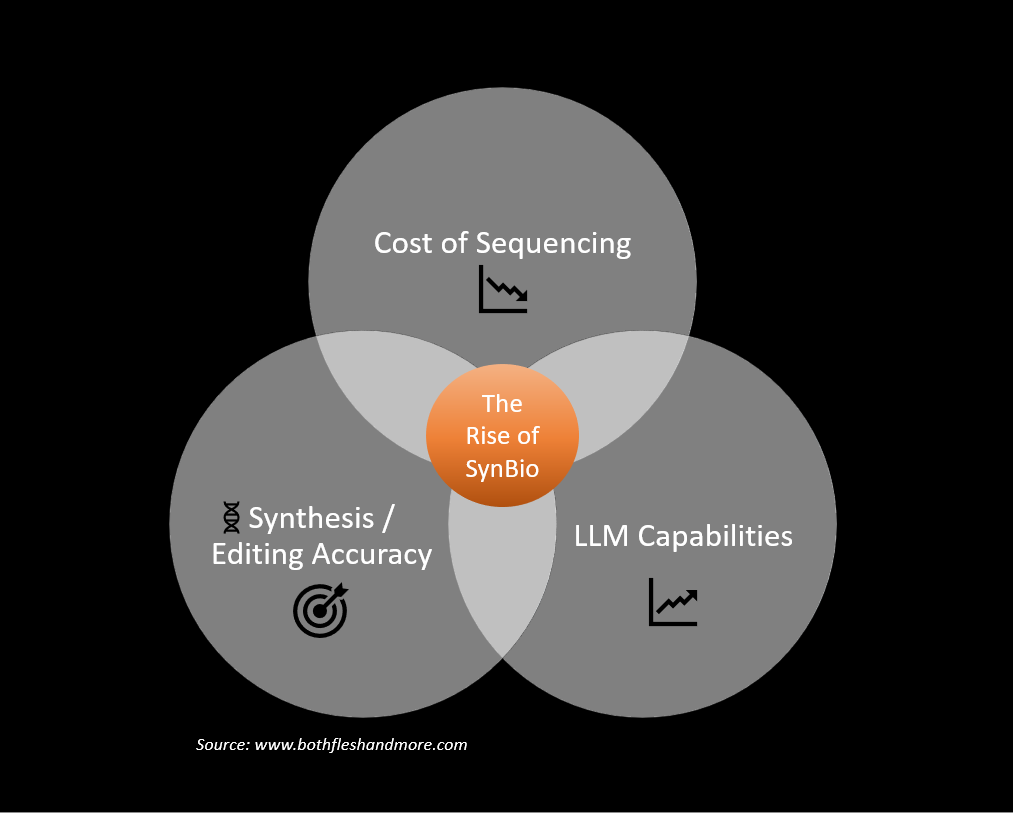
The increasing availability of large datasets - driven in part by the rapidly decreasing cost of sequencing genomes
The rise of advanced neural networks - powered by the acceleration in computational resources and processors for AI applications
Continued advances in methods to precisely edit and synthesize strands of DNA
Large Data Sets
In biology, this bucket needs work. A key driver behind the success of OpenAI’s transformer models is the unending data available on the internet on which to train. Outside of protein folding, few problem sets in biology have the data quantum necessary to unleash AIs full potential. To have a prayer at beginning to decipher the language of life, we need to feed the beast.
Fortunately, more data is coming… fast. The US$2.7b required to sequence the first human genome during the Human Genome Project has been aggressively surrendering to deflationary technological forces - outpacing even Moore’s law in cost reductions.

Source: National Human Genome Research Institute.
The plummeting costs and increasing demand for programmable molecules will drive a significant boost in DNA sequencing (along with corresponding phenotypic data) on which to uncover more relationships. Like the exponential curves in structured and unstructured data which accompanied Moore’s law in micro-electronics, bio-derived data sets are likely to follow a similar exponential path.
This bodes well for unleashing the full potential of AI’s recent acceleration in biology.
Artificial Intelligence
The relationship between genotypes (the genetic information of an organism) and phenotypes (the observable from the expressed genes) is complex for numerous reasons. First off, many traits are influenced by multiple genes (“polygenic” traits) making it difficult to decipher which combination is causing which trait. Incrementally, genes interact in complex ways - often enhancing or masking the impact of other genes in their expression. Secondly, environmental factors like nutrition, stress, temperature, chemical exposure and more can impact how underlying genes are expressed. The are more variables in play than just genotype input → phenotype output, further complicating our puzzle. Lastly, epigenetic factors - essentially “turning genes on and off” without modifying the order of the genome further complicate the causality.
Given the multivariate nature of the relationship, going from a gene sequence to a cell, not to mention an organism, requires unraveling this spiderweb of complexity. Fortunately, these are exactly the kind of relationships neural nets thrive at uncovering.
The AlphaFold project from Google’s DeepMind cracking the famous “protein folding problem” is perhaps the most prominent example. By showing the model the sequences and structures of ~100,000 known proteins, AlphaFold can now predict the structure of a protein from its amino acid sequence, “at scale and in minutes, down to atomic accuracy”. The project has opened up its database of ~200m protein structures to the scientific community, helping accelerate a broad range of scientific discoveries: from drug development in rare diseases to enzymes that can break down single-use plastics to combating anti-biotic resistance.
As data in biology becomes more ubiquitous, expect the compounding of AlphaFold-like discoveries to build on each another. Larger data sets = better models = more discoveries = more data we realize we should track.
As we decipher the language of life - these unique combinations of A, T, C, and Gs which make up the codons, which make up the amino acids, which construct the proteins, which power the cells which make up the organism - what is stopping us from moving from reading the code of life… to writing it?
It turns out, not much.
Synthesis - Editing / Creating New Life
In his recent book, “Editing Humanity” Kevin Davies traces the science, characters, implications and drama behind the recent CRISPR-Cas9 breakthrough now largely attributed to scientists Jennifer Doudna and Emmanuelle Charpentier. The “molecular scissors” discovery as the now-tired metaphor proclaims has ushered in a new generation of genome-editing tools giving humanity the power to accurately manipulate DNA.
Building on the initial discovery, David Liu’s team at the Broad Institute developed techniques for individual base pair editing - providing much needed precision in the high-stakes game of editing genomes to reduce “off-target” affects. These tools represent the first steps towards the coming “word processor” moment of genome editing.
Incrementally, the processes are beginning to scale; the artificial synthesis of DNA strands is becoming big business. Companies like Twist Bioscience, Integrated DNA Technologies, GenScript and more readily service customer requests for the production of high-quality synthetic DNA on a large scale. These ordered synthetic DNA strands can then be inserted into cells (think “software upgrade”) causing the cell’s machinery continuously churn out the desired sequence of new proteins.
Brave New World
The implications of the above are breathtaking. Involuntarily, the human brain leaps to questions of our own species’ genetic modifications. “The betterment of well beings” - a discussion fraught with knee-jerk hysteria, myriad ethical questions, and decades of regulatory red tape in virtually every case.
However, outside this can of worms, the possibilities are inspiring. Precisely manipulating electrons through silicon built the digital world around us in 75 years. The microprocessor, every appliance, the PC, the Internet, the Phone, the App Store - all through the manipulation of electrons.
What can we build once we have mastered the language of biology itself? What happens when we move from programming computers to programming cells? From resource extraction to growing biofuels? From food scarcity to genetically-induced abundance? From a life of pain to a baby free of sickle cell anemia or Huntington’s or a host of other life-threatening diseases?
The scope of programming cells spans almost every industry: from healthcare, to agriculture, to energy, to novel, more sustainable industrial materials.
To borrow an exert from Ginkgo Bioworks 10k:
“Synthetic biology, through the programming of DNA, enables the development of products made from all of these biological molecules, including DNA based gene therapies, mRNA vaccines, proteins and enzymes used as therapeutics, food ingredients or processing aids… antibiotics and other medicines, vitamins, fragrances, and even the building blocks of polymers that are today produced via petroleum”
Like many technical revolutions, there will be ups and downs. Hype cycles and deep corrections. The promise of utopia and the trough of disillusionment.
However, if you pick your head up and begin exploring the collision of DNA sequencing, AI’s acceleration, and the rise of precision genome editing tools, you might find a reason to smile.
A very solar punk future may be here before you know :).
Note to reader: I’m still getting up to speed on SynBio as well, so don’t take this as gospel. However, if interested to learn more in this fascinating field, I found the below helpful.
Good Reads on SynBio:
Editing Humanity by Kevin Davies
The Genesis Machine by Amy Webb + Andrew Hessel
The Age of Living Machines by Susan Hockfield
Regenesis by George Church and Ed Regis
The Century of Biology by Elliot Hershberg
The Bio Revolution by McKinsey (s/o to author @travers_nisbet)
Ginkgo Bioworks Annual Report
Notable Orgs:
If interested to get active at the intersection of crypto and synBio, please check out ValleyDAO. This is a new decentralized organization open to all aiming to fund and commercialize academic research in the synBio community.
Shameless plug for Chip War: The fight for the world’s most critical technology by Chris Miller